Did you know that you can navigate the posts by swiping left and right?
Research Paper Summary | Leaping Onto A Higher Degree Of Multiprogramming
05 Oct 2020
.
14 mins
:
readings
.
Comments
#academics
#review
#courses
#summary
#os
#operating-systems
#linux
#unix
Using Continuations to Implement Thread Management and Communication in Operating Systems, SOSO ‘91.

In the current times, with the advancement of information technology in leaps and bounds over the last decade, our devices hardly take a microsecond to juggle between dozens of open browser tabs, calculations, multimedia playback, and that video game with life-like realistic graphics. However, there is more than what meets the eyes since there can never be more programs running parallel than the available number of cores in a processor (usually 4-8 on modern processors).
The magic that serves our tasks in a seemingly parallel manner to us (the user) even when they are not running simultaneously has context switching at its core. It is with context switching that modern processors create the illusion of multitasking and steps to make the illusion more concrete is a bustling area of research.
a context switch is the process of storing the state of a process or thread so that it can be restored and resume execution at a later point.
In this writeup, we will be covering important research that set forth the motion for more contributions in the field of making simultaneous runs of tasks take less time, less space, and, most importantly, allow implementing high-level optimizations in the process of saving and restoring context - which was not possible hitherto because all context was stored in machine-dependent format. Towards the end, we would have answered the following broad question (we will be understanding the terms soon),
How can we reduce the time and space required by kernel threads in a process-based control flow management?
NOTE: The write up assumes that the reader has attended at least one basic operating system course and has familiarity with terms and functionality of an OS such as paging, address space, kernel, restoring stack, etc.
Introduction
Let’s travel back to the start of the 1990s (let’s just imagine, for now, time travel is not yet invented) - there are two ways that OS Kernels are handling control flows: the process model and the interrupt model.
control flow is the order in which individual statements, instructions, or function calls of an imperative program are executed or evaluated
In the process model, each thread gets a separate stack in the kernel’s address space and, consequently, this stack can be live for the entire life of the kernel thread allowing easy de-scheduling and re-scheduling. On the other hand, in the interrupt model, there is a single stack per processor that keeps track of all the execution in the kernel space. When a process is de-scheduled, it first has to save its state and restore the same at the time of re-scheduling.
It is very tempting to outrightly consider interrupt model to be better as the saving of space is multi folds compared to process model; however, the interrupt model is not friendly to work with as for every blocking process, a separate interrupt code will be required and this is impractical when aiming to be hardware agnostic and work independently of the underlying processor architecture. The process model, with its separate stack for each kernel thread, also provides ease of programmability as there are fewer security concerns and limitations on referencing pageable memory.
The process model has two underlying problems, which if solved will make it best to deploy in kernels that need to support multiple processor architectures and do not want to rely on writing interrupt codes for all possible blocking scenarios. Firstly, it takes up a large amount of memory since each thread is given a separate stack and the stack lives throughout the life of the thread. These stacks are stored in the kernel space implying that the current state is represented in a machine-dependent manner, leading us to the second issue that process model cannot support transfer control optimizations since high-level analysis is not possible by other threads.
The paper, after failed attempts on other methods, comes down to implement continuations to manage control flow and provide a high-level abstraction and optimization opportunity.
In computer science, a continuation is an abstract representation of the control state of a computer program.
Continuation is not a new invention, they were being used in multiple functional programming languages to save and restore the execution state. However, it was for the first time that they were being used on the kernel level (in Mach 3.0 Kernel in the paper) to manage control flow.
In the pursuit of a high-level easier to program, optimize, and analyze structure, we also come across many trade-offs and instances of overlooking which can lead to more harm than good.
Brief History Of Mach Kernel
Having looked at the general issues of the process model, let’s briefly learn about why Mach kernel uses and what are the drawbacks currently faced.
Mach 3.0, like previous generations of Mach, is based on Accent kernel which has always used the process model, and hence it was impractical to alter it completely to change to interrupt model. Another factor weighing in here, in the first version of Mach, was the requirement of supporting Unix kernel services and Unix worked on the process model.
It is only obvious to wonder that if Accent kernel could use the process model and work efficiently, what’s the issue with Mach? The answer lies in the fact that while Mach kernel is aimed to be architecture agnostic, Accent kernel used microcode associated with architecture to perform the same operations more efficiently.
Microcode is a computer hardware technique that interposes a layer of organization between the CPU hardware and the programmer-visible instruction set architecture of the computer.
Another feature of Mach, not in Accent, is having one kernel stack per-processor. This is aimed at reducing the cache and TLB misses as cache-aware multiprocessors are more efficient with per-processor data structures and the rate of cache misses grows with higher processor speed, making data structure operations’ efficiency very crucial.
Context Switching With Continuations
The implementation of continuations in the paper provides the kernel service the option to use either the process model or a modified interrupt model under which the process stores it’s context in a continuation and restores from thereon. This model of control flow management provides the following benefits:
- Allows backward compatibility with services using the process model.
- Advantages of the interrupt model and allowing service to choose the data it wants to store, saving space.
- Continuations are machine-independent allowing portability and high-level analysis of the stored context by other threads (leading to advantages such as stack handoff) increasing the scope of run-time optimizations.
Continuations In Action
There are two broad types of control transfers that can leverage continuations:
- transfer that occurs at the user/kernel boundary when a thread traps or faults out of user space and into the kernel
- within kernel when one thread transfers control to another
In the two scenarios, the kernel services use continuations in the following manner:
- Kernel entry routines create a continuation which when called from the kernel returns control to the user level. Continuations can be invoked with the return code for a system call or without arguments as in case of exceptions and interrupts (which do not return value to user programs).
- Within the kernel, continuations can be created by passing a function pointer to the kernel procedure that blocks threads. This function becomes the thread’s continuation and is stored in the kernel’s machine-independent thread data structure.
There is a caveat to note here that differentiates a Continuation from any other function - continuation function can only return other functions or continuations. So, for instance, a function returning 0 cannot be used as a continuation.
For context storage, the thread is provided with 28 bytes of scratch data and any memory required above the same can be used with the help of an additional data structure. Here, in continuations, backward compatibility to process model is ensured by passing null as a continuation.
Converting Services To Use Continuations
The key highlight of the paper and sheer ingenuity of the authors is providing a very simple method of converting existing kernel services to use continuations and easiness of the conversion makes the process practical.
Using continuation is most effective for services that do blocking calls and only need to store a small amount of data for resumption. The steps for conversion are as follows:

- Separate the function into two separate parts - pre block and post block.
- Define a new function for the post block portion and keep only pre block in the original function.
- Store any required data in the scratch area in pre block and load from the same in post block function.
- Change the return of the post block function to call another function (could be an exit or main function body in case of an infinitely running service) or continuation.
General High-Level Optimizations
With providing continuations, a large number of optimizations are possible. The authors highlight a few of them:
- Stack Discarding: A thread can choose to discard it’s stack if the same is not required after resumption from the block.
- Stack Handoff: The following thread can be given access to the previous thread’s discarded stack facilitating direct passing on information without copying or any other overhead.
- Continuation Recognition: Since continuation is a function pointer, it can be analyzed on a high-level and, maybe, a more specific and faster code sequence can be used.
The below figure illustrates the usage of the above optimizations in Cross Address Space RPC.
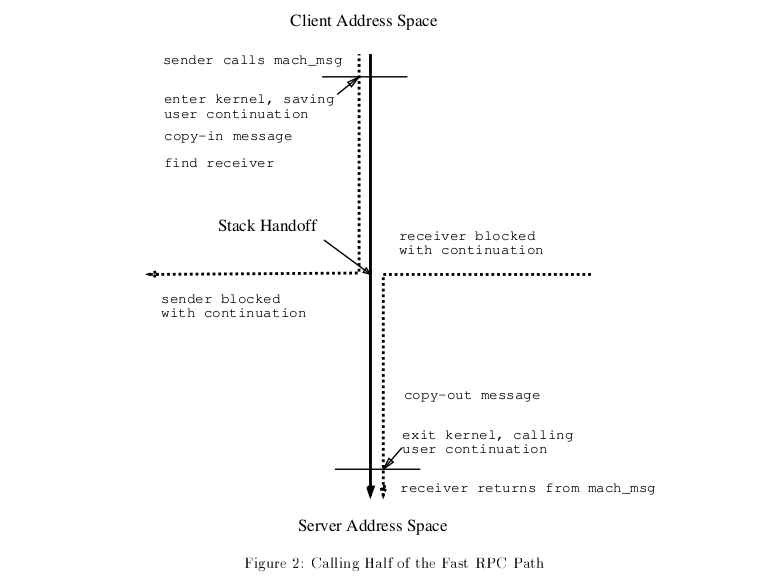
Architecture Portability
By dividing the kernel into two separate broad categories of modules an architecture-independent solution is achieved for implementing continuations. The machine-independent modules implement the Mach kernel interfaces (and the continuations) as shown below, while machine-dependent modules manage hardware interactions.


Performance Evaluations
All seems good on the paper and theoretical groups, and the same is reflected in the performance results. The performance tests compare three different versions of Mach kernels - Mach 2.5, MK32, and MK40, running on machines with identical hardware. The MK40 kernel has the implementation of continuations, MK32 includes optimizations in cross-address space RPC service, and Mach 2.5 does neither.
Frequency Of Usage
The performance improvement provided by continuations depends highly on the percentage of control flows that make use of continuations as process model is also made available.
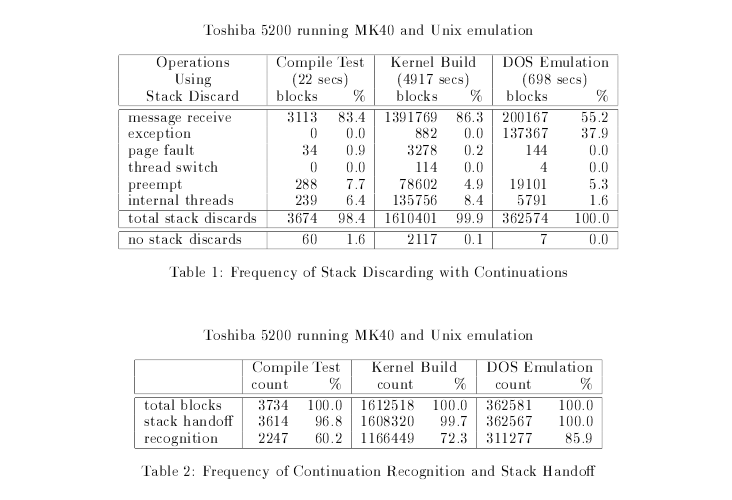
As seen from the result, barring control flows which have to necessarily use process model such as memory allocation, lock acquisition, page faults, etc.), almost all control flows (99%) happen through continuations. This also provides a strong case for the fact that most of the threads never needed to store large amounts of space when getting de-scheduled and simply are discarding their stacks.
Space-Time Savings
Saving space and time is the elephant in the room the paper tries to address.
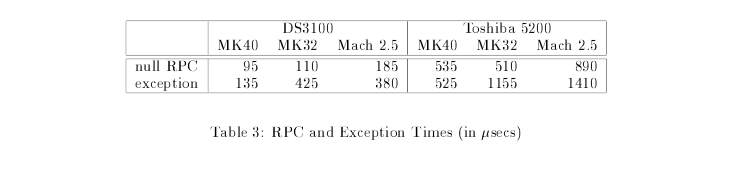
In the case of exception handling, MK40 with continuations is 2-3 folds faster than MK32. However, the same is not the case with RPC calls since MK32 is already optimized to handle RPC and the performance is similar to MK40. Mach 2.5 is far slower and hence proves that continuations provided faster results, at least in RPC and exception handling.
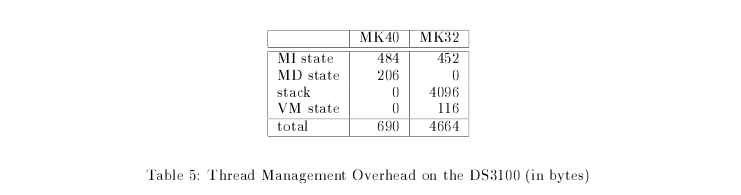
Due to optimizations, namely, stack discard and stack handoff, MK40 has average kernel memory consumption at 14% of MK32. The fact that MK40 allows threads to store data beyond 28 bytes in an additional data structure also helps in the same.
Conclusion
Continuations were a substantial step towards multiprogramming, and the key feature, alongside saving memory and time, is the future scope it leaves for optimizations via analysis of the continuation pointer. For a kernelized operating system such as Mach that has lesser blocks and blocks that are not deeply nested, continuations can provide multifold performance improvements in terms of space and time.
The high-level approach of continuations packs a few tradeoffs, most notably an inclination towards overuse and falling completely into the interrupt model. It also introduces a higher degree of fragility into the code as there are assumptions regarding callers when using machine-independent modules to implement continuations.
All in all, it is only justifiable to leave scope for errors by making high-level abstractions and decreasing limitations and interactions. It’s just like how we have come a long way riding on abstractions, making hardware more powerful since we have lost the early day ways of writing machine code.
Abstractions force advancements in hardware as we start making more abstractions on top of them.

I'm intrigued by human psychology and code backend for videogames. I live with a philosophy to be simple, true, and kind always. I enjoy taking days slowly and writing when I learn something new - ah! that reminds me, I enjoy learning from new experiences a lot.